Self-Supervised Learning คือการปฏิวัติวิธีการฝึก AI จากการพึ่งพามนุษย์อย่างหนัก ไปสู่การให้ AI สร้างโจทย์และเรียนรู้เองจากข้อมูลมหาศาลที่มีอยู่แล้วในโลกดิจิทัล
สำหรับบุคคลทั่วไป การเข้าใจ SSL ไม่จำเป็นต้องรู้สมการคณิตศาสตร์ แต่เพียงเข้าใจว่า นี่คือวิธีที่ทำให้ AI ฉลาดขึ้นโดยใช้ข้อมูลที่มีอยู่แล้วรอบตัวเรา และผลลัพธ์คือเทคโนโลยีที่สามารถช่วยชีวิตเราได้ในหลายด้าน ตั้งแต่การค้นหาข้อมูล ไปจนถึงการแพทย์และการสื่อสาร
ในยุคที่ข้อมูลดิจิทัลท่วมท้น โลกของปัญญาประดิษฐ์ (AI) กำลังเผชิญโจทย์ใหญ่ ข้อมูลมีมากมาย แต่การ “ติดป้ายกำกับ” หรือการจัดหมวดหมู่ข้อมูลเหล่านั้นกลับใช้แรงงานและค่าใช้จ่ายมหาศาล เช่น การบอกว่าในภาพหนึ่งมีแมวหรือสุนัข ต้องอาศัยคนมานั่งทำทีละภาพ ซึ่งไม่สอดคล้องกับความเร็วของโลกดิจิทัลที่เปลี่ยนแปลงทุกวินาที
Self-Supervised Learning (SSL) จึงถือกำเนิดขึ้นในฐานะวิธีการใหม่ที่ให้ AI “สร้างโจทย์เองและหาคำตอบเอง” โดยไม่ต้องพึ่งพาป้ายกำกับจากมนุษย์มากนัก เป็นการผสมผสานระหว่าง supervised learning (การเรียนรู้จากข้อมูลที่มีป้ายกำกับ) และ unsupervised learning (การเรียนรู้จากข้อมูลดิบที่ไม่มีป้ายกำกับ)
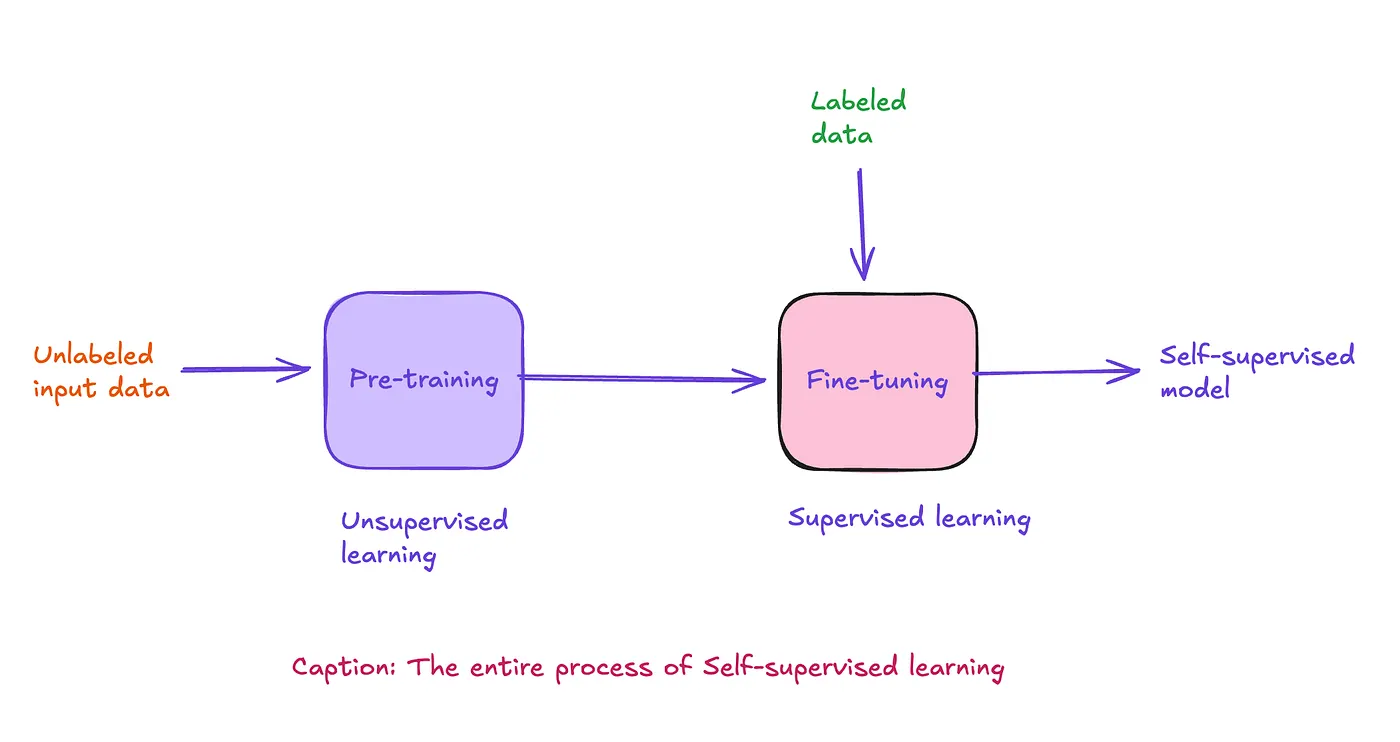
Self-Supervised Learning คืออะไร
แนวคิดหลักของ SSL คือ การสร้างสัญญาณกำกับจากข้อมูลเอง ตัวอย่างเช่น
- ในงานประมวลผลภาษา (NLP) โมเดลจะซ่อนบางคำในประโยค แล้วฝึกให้ AI เดาคำที่หายไป เช่น โมเดล BERT
- ในงานภาพ (Computer Vision) โมเดลอาจซ่อนบางส่วนของภาพ แล้วให้ AI เติมเต็มช่องว่าง เช่น Masked Autoencoders (MAE)
- ในงานเสียง โมเดลอย่าง Wav2Vec 2.0 จะซ่อนบางช่วงของคลื่นเสียง แล้วให้ AI เดาว่าส่วนที่หายไปคืออะไร
วิธีนี้ทำให้ AI สามารถเรียนรู้โครงสร้างและความสัมพันธ์ในข้อมูลได้เอง โดยไม่ต้องอาศัยการติดป้ายกำกับจากมนุษย์ทุกครั้ง
ทำไม SSL ถึงสำคัญ
- ลดค่าใช้จ่ายในการติดป้ายกำกับข้อมูล
การสร้างชุดข้อมูลที่มีป้ายกำกับเป็นงานที่ใช้แรงงานสูง SSL ช่วยลดภาระนี้ลงอย่างมาก - ใช้ประโยชน์จากข้อมูลมหาศาลที่ยังไม่ได้ใช้
โลกออนไลน์เต็มไปด้วยข้อความ รูปภาพ และเสียงที่ไม่มีป้ายกำกับ SSL สามารถนำข้อมูลเหล่านี้มาใช้ฝึกโมเดลได้ - สร้างโมเดลที่ยืดหยุ่นและทรงพลัง
โมเดลที่ผ่านการฝึกด้วย SSL มักจะเข้าใจโครงสร้างข้อมูลได้ลึกกว่า และสามารถนำไปปรับใช้กับงานที่หลากหลาย เช่น การแปลภาษา การค้นหารูปภาพ หรือการรู้จำเสียง
ตัวอย่างโมเดลที่ใช้ SSL
- BERT: โมเดลภาษาที่ใช้การซ่อนคำในประโยคแล้วให้ AI เดา ทำให้เข้าใจความหมายเชิงบริบทได้ดี
- SimCLR และ BYOL: โมเดลภาพที่ใช้เทคนิค contrastive learning โดยเปรียบเทียบภาพที่ถูกแปลงให้แตกต่างกัน เพื่อให้ AI เข้าใจว่าเป็นภาพเดียวกัน
- CLIP: โมเดลที่เชื่อมโยงข้อความกับภาพ เช่น เมื่อเราพิมพ์ว่า “สุนัขนั่งบนโซฟา” โมเดลสามารถค้นหาภาพที่ตรงกับคำอธิบายได้
- Wav2Vec 2.0: โมเดลเสียงที่ช่วยให้ AI เข้าใจเสียงพูดได้แม่นยำขึ้น โดยไม่ต้องใช้ข้อมูลเสียงที่มีการถอดคำพูดจำนวนมาก
การประยุกต์ใช้ในชีวิตจริง
- การค้นหาข้อมูลอัจฉริยะ: ระบบค้นหาที่เข้าใจความหมาย ไม่ใช่แค่คำตรงตัว
- การแปลภาษา: โมเดลที่เรียนรู้จากข้อความมหาศาล สามารถแปลได้แม่นยำขึ้นแม้ในภาษาที่มีข้อมูลจำกัด
- การแพทย์: วิเคราะห์ภาพถ่าย MRI หรือ X-ray โดยไม่ต้องมีแพทย์มาติดป้ายกำกับทุกภาพ
- สื่อสังคมออนไลน์: การตรวจจับเนื้อหาที่ไม่เหมาะสมหรือการแนะนำคอนเทนต์ที่ตรงใจผู้ใช้
ความท้าทายและข้อควรระวัง
แม้ SSL จะทรงพลัง แต่ก็มีข้อท้าทาย
- คุณภาพของข้อมูลดิบ: หากข้อมูลที่ใช้ฝึกมีอคติหรือไม่สมบูรณ์ โมเดลก็จะเรียนรู้อคติเหล่านั้นไปด้วย
- ความซับซ้อนทางเทคนิค: การออกแบบโจทย์ให้ AI เดาเองไม่ใช่เรื่องง่าย ต้องอาศัยความเข้าใจเชิงคณิตศาสตร์และทฤษฎีสารสนเทศ
- การตีความผลลัพธ์: โมเดลที่เรียนรู้เองอาจสร้างความเข้าใจที่มนุษย์ตีความได้ยาก
…..
เรียบเรียงโดย AiNextopia
Source: A Beginner’s Guide to Self-Supervised Learning / Medium.com